Clear Sky Science · ar
تحسين تنبؤ الدرجة متعددة الجينات للمجموعات الممثلة تمثيلاً ناقصاً عبر التعلم النقلي
لماذا قد لا تنطبق درجة المخاطر الجينية على حالتك
تُستخدم «درجات المخاطر» الجينية بشكل متزايد لتقدير فرصة إصابة شخص بحالات شائعة مثل السكري وأمراض القلب أو ارتفاع ضغط الدم. لكن معظم هذه الدرجات بُنيت باستخدام بيانات DNA من أشخاص ذوي أصول أوروبية. ونتيجة لذلك، غالباً ما تكون التنبؤات ضعيفة بالنسبة لأشخاص من خلفيات أخرى، مما يثير قلقاً حول العدالة والفائدة في الممارسة الطبية الحقيقية. تطرح هذه الدراسة سؤالاً بسيطاً: هل يمكننا إعادة استخدام ما تعلمناه من مجموعات بيانات أوروبية كبيرة لبناء درجات جينية أفضل وأكثر إنصافاً للمجموعات الممثلة تمثيلاً ناقصاً—دون مشاركة بيانات أحدهم الخام؟
من ملايين مؤشرات الـDNA إلى درجة مخاطرة واحدة
تشبه الدرجة متعددة الجينات بيان درجات يجمع التأثيرات الصغيرة لعدد كبير من المؤشرات الجينية المنتشرة عبر الجينوم. يحصل كل مؤشر على وزن يعكس مدى ارتباطه بصفة ما، استناداً إلى دراسات جينية واسعة النطاق. عندما تتضمن هذه الدراسات في الغالب أوروبيين، تميل الدرجة الناتجة للعمل بشكل أفضل لدى الأوروبيين. الاختلافات في الخلفيات الجينية—مثل مدى شيوع متغيرات DNA معينة وكيف تُورّث معاً—تعني أن الأوزان نفسها غالباً ما تفشل لدى سكان أفارقة أمريكيين أو من أصل لاتيني وغيرهم. وجمع مجموعات بيانات متساوية الحجم لكل مجموعة مكلف وبطيء، لذا لجأ المؤلفون إلى استراتيجية تعلم آلي تُسمى التعلم النقلي: بدلاً من البدء من الصفر في كل مجموعة، يصلحون نموذجاً موجوداً تم تدريبه في مكان آخر.
كيف نُقْتَبس المعرفة دون مشاركة البيانات الخام
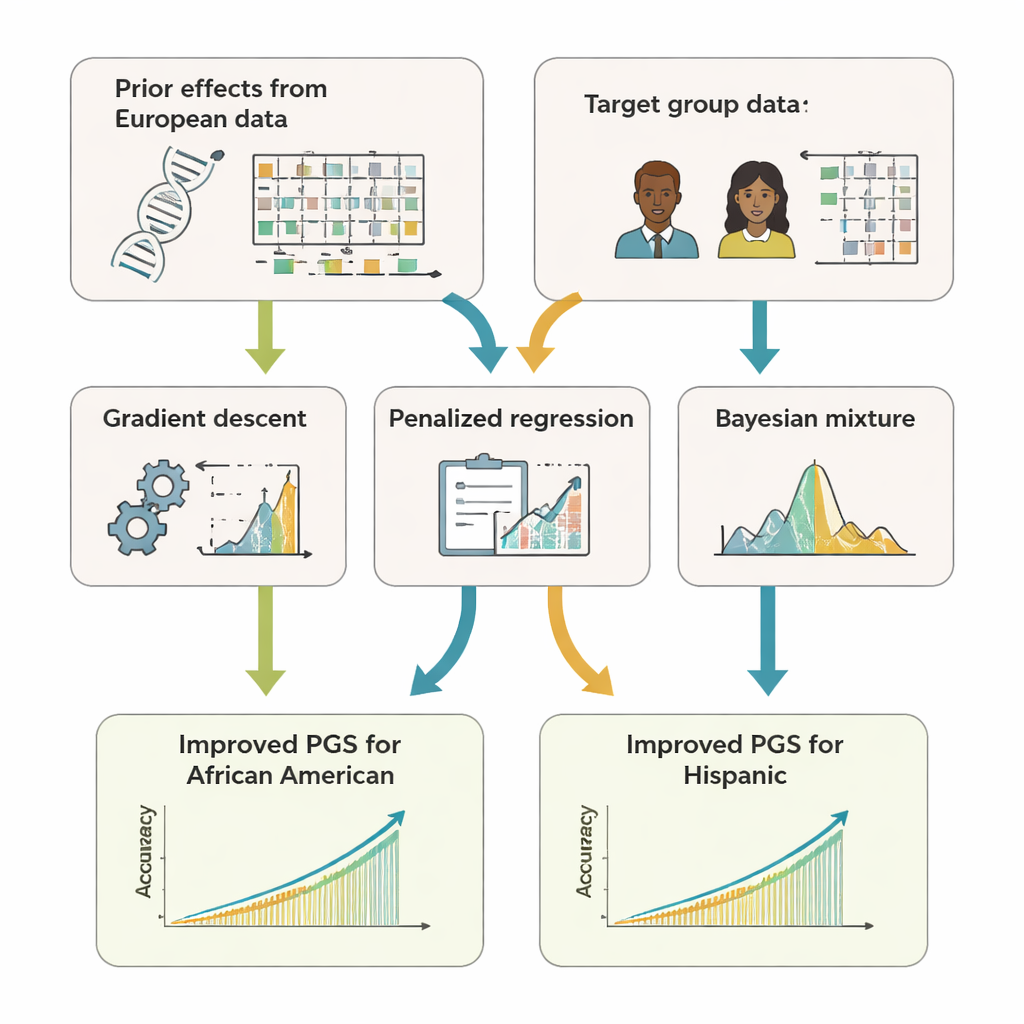
طوّر الفريق برنامجاً مفتوح المصدر بلغة R اسمه GPTL ينفذ ثلاث طرق للتعلم النقلي لدرجات جينية. تبدأ الثلاثة جميعها بتقديرات حالية لتأثيرات الـDNA تم الحصول عليها من مجموعة بيانات كبيرة ذات أصول أوروبية، ثم تعدّل تلك التقديرات بلطف باستخدام بيانات من المجموعة المستهدفة، مثل الأفارقة الأمريكيين أو ذوي الأصول اللاتينية. طريقة واحدة تضبط أوزان الأوروبيين خطوة بخطوة باستخدام النزول التدرجي وتتوقف مبكراً، قبل أن تمحوها كلياً. الطريقة الثانية، المسماة الانحدار الموقوف (penalized regression)، تسحب التقديرات الجديدة باتجاه القيم الأصلية ما لم تقدّم بيانات المجموعة المستهدفة دليلاً قوياً على خلاف ذلك. الطريقة الثالثة، نموذج خليط بايزي، تتيح لكل مؤشر جيني اختيار مصدر معلومات من عدة مصادر—مثل مجموعات أصول مختلفة أو حتى خيار «بدون تأثير»—ثم تمزجها حسب مدى تفسيرها لبيانات المجموعة المستهدفة.
اختبار الطرق في الممارسة
لاختبار مدى فاعلية هذه المقاربات، استخدم المؤلفون كل من محاكاة حاسوبية وبيانات حقيقية من مئات الآلاف من المتطوعين في UK Biobank وبرنامج الأبحاث الأمريكي All of Us. ركزوا على المشاركين الأفارقة الأمريكيين واللاتينيين كمجموعات مستهدفة واستخدموا بيانات ذات أصول أوروبية كمصدر أساسي للمعلومات السابقة. عبر 11 صفة—بما في ذلك الطول، ومؤشر كتلة الجسم، وشحميات الدم، وضغط الدم، ومؤشرات وظائف الكلى—تنبأت درجات التعلم النقلي باستمرار بشكل أفضل من الدرجات المبنية فقط داخل المجموعة المستهدفة أو المعاد استخدامها مباشرةً من الأوروبيين. في كثير من الحالات، كانت دقتها مساوية أو تفوق قليلاً طرق «متعددة الأنساب» الأكثر تعقيداً التي تتطلّب دمج بيانات خام من عدة مجموعات. والأهم أن طرق GPTL تحتاج فقط إلى إحصاءات مُجمّعة—أرقام ملخّصة حول التأثيرات الجينية—حتى تتمكن المؤسسات من التعاون دون كشف سجلات وراثية على مستوى الأفراد.
عندما لا تكون الكمية الأكبر من الـDNA دائماً أفضل
درس الباحثون أيضاً كيفية اختيار المؤشرات الجينية التي يجب تضمينها. على عكس الاعتقاد الشائع أن استخدام كل مؤشر متاح مفيد دائماً، وجدوا أنه بالنسبة للمجموعات الأفريقية الأمريكية ولا سيما اللاتينية، قد يضرّ تضمين ملايين الإشارات الضعيفة جداً بالأداء، خصوصاً عند استخدام تمثيلات مبسطة للغاية للارتباطات الجينية. التركيز على المؤشرات المدعومة بشكل أفضل واستخدام معلومات أغنى حول كيفية وراثة المتغيرات معاً غالباً ما أدى إلى درجات أكثر دقة. وأظهرت الدراسة أيضاً أن إضافة معلومات سابقة من مجموعات أنساب متعددة ونمذجة الفروق بين السكان بعناية حسّنت التنبؤات أكثر.
ماذا يعني هذا لتنبؤ جيني أكثر عدلاً
بالنسبة للسكان غير الأوروبيين، قد تؤدي درجات المخاطر الجينية الجاهزة اليوم إلى أداء أضعف بفوارق كبيرة، مما قد يوسّع الفوارق الصحية. تُظهر هذه الدراسة أن التعلم النقلي—تصحيح ذكي للدرجات القائمة على الأوروبيين باستخدام مجموعات بيانات متواضعة من المجموعات الممثلة تمثيلاً ناقصاً—يمكن أن يسد جزءاً كبيراً من هذه الفجوة. عملياً، يعني ذلك أن أنظمة الرعاية الصحية والباحثين يمكنهم بناء أدوات جينية أكثر دقة وإنصافاً دون تجميع البيانات الخام عبر مؤسسات أو أنساب، مما يخفف مخاوف الخصوصية. وعلى الرغم من أنه لا توجد طريقة واحدة ستكون الأفضل لكل صفة ولكل مجموعة سكانية، يظهر مجموعة أدوات GPTL أن التنبؤ الجيني الأكثر عدلاً متاح تقنياً إذا عاملنا النماذج السابقة كنقاط انطلاق قابلة للتكييف بدلاً من منتجات ثابتة.
الاستشهاد: Wu, H., Pérez-Rodríguez, P., Boehnke, M. et al. Improving polygenic score prediction for underrepresented groups through transfer learning. Nat Commun 17, 1973 (2026). https://doi.org/10.1038/s41467-026-68696-7
الكلمات المفتاحية: درجات المخاطر متعددة الجينات, التعلم النقلي, التنبؤ الجيني, الفوارق الصحية, علم وراثة السكان