Clear Sky Science · ar
أفضل الممارسات والأدوات في R وPython للمعالجة الإحصائية وتصوير بيانات الليبيدوميكس والميتِبولوميكس
لماذا يهم تحويل أرقام المختبر إلى صور واضحة
تستطيع الأجهزة الحديثة الآن قياس آلاف الجزيئات الصغيرة — الدهون والمواد الأيضية الأخرى — من قطرة دم أو نسيج واحد. تحتوي هذه القياسات على دلائل حول مخاطر الأمراض، واستجابات العلاج، وكيف يتفاعل جسمنا مع النظام الغذائي أو التقدم في السن. لكن النتائج الخام ليست إجابة جاهزة: إنها جدول ضخم من الأرقام يحتاج إلى تنظيف وتحليل وتحويل إلى صور مفهومة. تشرح هذه المقالة كيف يمكن للباحثين استخدام لغتي البرمجة الشائعتين، R وPython، للقيام بذلك بشكل موثوق وشفاف، وبرسومات بجودة النشر.
من القياسات الكيميائية إلى جداول بيانات معقدة
في الليبيدوميكس والميتِبولوميكس، تولد أجهزة الطيف الكتلي والكروماتوغرافيا مجموعات بيانات كبيرة حيث يمثل كل صف عيّنة وكل عمود جزيئاً. نادراً ما تتصرف هذه الجداول مثل أمثلة الكتب الدراسية المنظمة. فهي تحتوي على قيم مفقودة، وقيم شاذة، وتوزيعات مائلة حيث تظهر بعض الجزيئات مستويات مرتفعة للغاية. قد تمتد تراكيز المركبات عبر عدة مراتب من الكُبرى، وقد تتأثر بالعمر، والجنس، والنظام الغذائي، والأدوية، والإيقاعات اليومية، ومشاكل تقنية مثل انحراف الجهاز أو تأثيرات الدفعات. أصدرت مجموعات خبراء دولية إرشادات لتوحيد كيفية جمع العينات ومعالجتها والإبلاغ عنها، لكن حتى مع ممارسات مخبرية جيدة، يظل المعالجة الإحصائية الدقيقة ضرورية لاستخلاص إشارات بيولوجية حقيقية من هذا الخلف الضوضائي.
تنظيف وتحضير الأرقام
قبل أن تكون أي مقارنة بين المجموعات السليمة والمريضة ذات معنى، يجب تحضير البيانات. يصف الاستعراض كيف تنشأ القيم المفقودة — نتيجة حوادث عشوائية، أو قيود الجهاز، أو تداخل الإشارة — ويشرح متى يمكن تجاهلها بأمان، ومتى ينبغي إعادة القياس، وكيف يمكن تقديرها بشكل معقول (تعويضها) باستخدام أساليب مثل الجيران الأقرب k، أو الغابات العشوائية، أو بدائل بسيطة بقيم منخفضة. بعد ذلك يستعرض المؤلفون استراتيجيات التطبيع التي تقلل التباين غير المرغوب فيه، على سبيل المثال بتصحيح تأثيرات الدُفعات باستخدام عينات مراقبة الجودة أو بتعديل فروق كمية العينة. ثم يناقشون تحويلات مثل اللوغاريتمات — التي تقوّم الذيل الطويل الأيمن في البيانات — وطرق المقياس التي تضع جميع الجزيئات على أساس قابل للمقارنة حتى لا تهيمن المركبات ذات التغير العالي على التحليلات اللاحقة. 
الاختبارات الإحصائية والقصص البصرية
بمجرد إعداد البيانات بشكل صحيح، تدخل مجموعة من الأدوات الإحصائية حيز التطبيق. بالنسبة للجزيئات الفردية، يمكن للباحثين حساب نسب التغير واستخدام اختبارات كلاسيكية مثل اختبار t أو نظيراتها غير المعلمية (مثل اختبار مان–ويتني) لطرح سؤال ما إذا كانت المستويات تختلف بين المجموعات. للمقارنات التي تشمل عدة مجموعات، تُعرض طرق مثل ANOVA أو اختبار كروسكال–واليس، مصحوبة بإجراءات بعدية لتحديد أي المجموعات تختلف. تزول فعالية هذه الاختبارات عندما تُعرض نتائجها بصور واضحة. تبرز المقالة مخططات الصندوق (بما في ذلك نسخ محسنة للبيانات المائلة)، ومخططات الكمان، ومخططات البركان التي تجمع بين حجم التأثير والأهمية الإحصائية. بالنسبة للدهون، تُوصف تصورات أكثر تخصصاً، مثل شبكات الدهون التي تُظهر تغيّرات منسقة عبر فئات كاملة، ومخططات سلاسل الأحماض الدهنية التي تكشف أنماط طول سلسلة الكربون وتشبعها.
رؤية الأنماط عبر متغيرات عديدة دفعة واحدة
بما أن كل عيّنة قد تحتوي على مئات أو آلاف الجزيئات المقيسة، تصبح الطرق متعددة المتغيرات ضرورية. يشرح الاستعراض كيف تُضغط هذه التعقيدات عن طريق تحليل المركبات الرئيسي (PCA) إلى محاور جديدة قليلة تلتقط اتجاهات التغير الرئيسية، مما يمكّن من فحوصات سريعة لفصل المجموعات، أو تأثيرات الدُفعات، أو استقرار التحليل. يمكن للطرق غير الخطية الأكثر تقدماً، بما في ذلك t-SNE وUMAP، الكشف عن تجمعات وهياكل دقيقة في الفضاء عالي الأبعاد. في الحالات التي يكون الهدف فيها تصنيف العينات — على سبيل المثال تمييز المرضى عن الضوابط — يصف المؤلفون طرقاً مُشرفَة تعتمد على الانحدار الجزئي الأصغر وممتداته المتعامدة (PLS-DA وOPLS-DA). تربط هذه الطرق بين الملفات الجزيئية وتسميات العينات، وتدعم اختيار السمات، وغالباً ما تُلخّص برموز نقاط، ومخططات تحميل، ومنحنيات خصائص التشغيل المستقبلية.
مجموعة أدوات عملية في R وPython
لمساعدة المبتدئين على الانتقال من النظرية إلى التطبيق، تستعرض المقالة نظاماً إيكولوجياً واسعاً من حزم البرمجيات. في R، تسهّل مجموعات مثل tidyverse وtidymodels تنظيف البيانات والنمذجة، بينما تجعل ggplot2 والحزم المضافة مثل ggpubr وggstatsplot وtidyplots من السهل إنتاج رسوم ذات جودة نشر. تتعامل مكتبات متخصصة مع PCA والتجميع ونماذج PLS، وتدعم حزم Bioconductor خرائط حرارية معقدة ورسوم تفاعلية. في بايثون، توفر pandas التعامل مع الجداول، بينما تغطي matplotlib وseaborn وplotly التصوير، ويقدم scikit-learn مجموعة واسعة من أساليب متعددة المتغيرات. على امتداد المقالة، يؤكد المؤلفون على أمثلة خطوة بخطوة متاحة في كتاب GitBook مصاحب، حتى يتمكن القراء من تكرار سير العمل وتكييفه مع بياناتهم الخاصة. 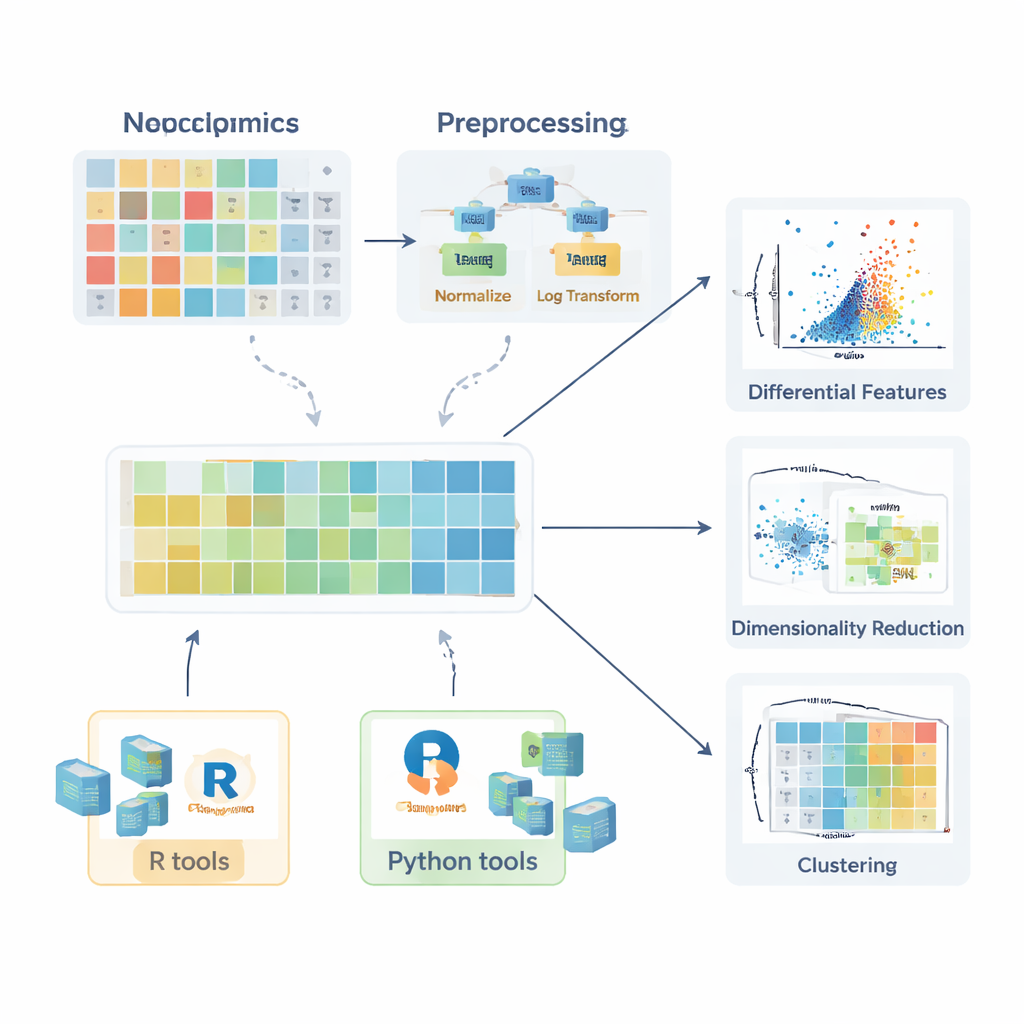
تحويل الكيمياء المعقدة إلى استنتاج موثوق
تختم المقالة بأن الوعد الحقيقي لليبيدوميكس والميتِبولوميكس لا يكمن فقط في الأجهزة القوية، بل في مدى عناية معالجة مخرجاتها وتصويرها. من خلال اتباع ممارسات إحصائية جيدة، واستخدام أدوات مفتوحة وموثقة جيداً في R وPython، والاعتماد على أمثلة شفرة مشتركة، يمكن للباحثين بناء خطوط أنابيب قوية وقابلة للتكرار. هذا يحسن الفرص في أن تتحول الأنماط الموجودة في الجزيئات الصغيرة إلى مؤشرات حيوية موثوقة، وفهم أفضل لآليات المرض، ونُهُج طبية أكثر تخصيصاً تفيد المرضى في النهاية.
الاستشهاد: Idkowiak, J., Dehairs, J., Schwarzerová, J. et al. Best practices and tools in R and Python for statistical processing and visualization of lipidomics and metabolomics data. Nat Commun 16, 8714 (2025). https://doi.org/10.1038/s41467-025-63751-1
الكلمات المفتاحية: ليبيدوميكس, ميتِبولوميكس, تصوير البيانات, برمجة R, بايثون